
2023. 9. 11. 20:20ㆍ자연어처리

우리가 현재 사용하고있는 챗 GPT는 3.5 모델이 기본이다. 하지만 GPT 4 역시 출시되었고 이는 유료버전에만 지원한다.
???: 세종대왕이 맥북프로 던졌다는데?

GPT4 는 GPT 3.5에 비해
을 지원한다고 하는데 무엇이 달라졌길래 그럴까?
먼저 GPT4는 오픈소스가 아니다. open AI는 논문이 아닌 테크니컬 리포트의 형태로만 공개하였다.
정확한 모델의 구조, 파라마터 수 등은 공개하지 않고, High - Level overview와 성능 평가 결과만을 보여주었다.
GPT4 와 GPT3.5의 큰 변화는 Input으로 이미지를 받을 수 있다는 점이다. 우리는 이를 Multi - modal 이라고 부른다.

또한 input의 길이가 대폭 늘어났다.
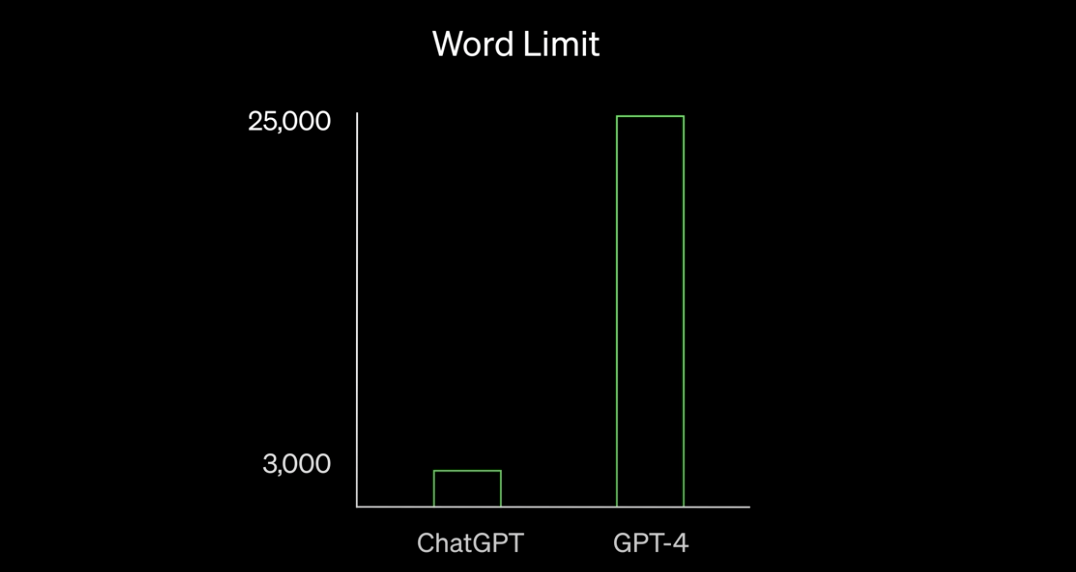
기존의 ChatGPT는 3천여개의 단어까지 인풋으로 받을 수 있는 반면에 GPT-4는 2.5만개의 단어까지 인풋으로 받을 수 있다.
또한 성능면에서 GPT4 가 이전의 모델들을 압도하는 성응을 보여주는데. 기본상식 테스트, 독해력 , 파이썬 코딩 등에서 크게 증가한 성능을 보인다.

논문이 공개되어있지 않아서 모델 구조, 학습 방법을 완전히 알 수는 없지만 리포트에서는 Post-training alignment process, 즉 학습 후 교정 과정을 통해 GPT의 가장 큰 한계라고 지적되는 팩트 체크(Factuality), 안정성(Safety)를 강화했다는 것을 강조한다.
GPT를 업그레이드하기 위해 쓰이는 방식은 Reinforcement Learning with Human Feedback (RLHF)이다.

Reinforcement Learning with Human Feedback (RLHF) 이란 말 그대로 사람이 직접 피드백을 주는 방식으로 언어모델을 최적화 하는 기법이다.
RLHF는 사람의 피드백을 활용하여 모델을 훈련시키며 주관적인 사람의 의견을 통해 데이터의 품질과 관련성을 개선하기 위해 설계되었다. 또한 RLHF에서는 사람들이 자연어 프롬프트나 입력 프롬프트를 통해 응답을 생성하고, 이러한 응답들의 선호도 순위를 생성하는 데 중점을 둔다.
이를 통해 RLHF는 모델이 더 나은 응답을 생성하도록 돕고, 언어 모델의 성능을 향상시킬 수 있다.

- GPT-3에서 RLHF를 추가해서 만든게 GPT-3.5
- GPT-3.5에서 멀티모달 + 더 많은 글자수 추론 추가한게 GPT-4
이라고 한다.
Reinforcement Learning with Human Feedback은 인간 Labeler의 데이터셋을 생성하기 위해선 파트 타임 직원을 고용해야 하기 때문에 비용이 많이 드는 문제가 있다. 또한 InstructGPT 논문에서 언급한 것처럼 RLHF은 언어 모델을 인간의 의도대로 alignment하기 위해 fine-tuning용 데이터셋을 얻을 때 다음과 같이 복잡하고 다양한 주관적인 요인에 영향을 받은 한계가 있다.
하지만 GPT 4의 한계 또한 여전하다.
1. 여전히 오류 가능성이 있다. 인공지능의 대표적인 허점인 할루시네이션 현상이 해결된 것이 아니다.
2. 폐쇄적인 GPT-4 기술 보고서인데 , 이는 개방과 공유를 강조하며 2015년 비영리 회사로 출범한 OpenAI는 ‘인류 모두를 위한 AI 개발’을 목표로 내걸고 기술 협력에 나섰던 행보와는 상이한 모습이기 때문
'자연어처리' 카테고리의 다른 글
| [논문리뷰] Template Controllable keywords-to-text Generation (0) | 2024.01.16 |
|---|---|
| 트랜스포머(Transformer) 가 뭘까 - 1 (0) | 2023.09.11 |
| Sequence - to - Sequence ( seq2seq ) (0) | 2023.09.08 |
| Gated Recurrent Unit , GRU ( 게이트 순환 유닛 ) (0) | 2023.09.07 |
| Long Short - Term Memory , LSTM (1) | 2023.09.07 |