
2023. 9. 11. 18:33ㆍ자연어처리
트랜스포머가 뭘까

아니다.

트랜스포머 모델은 Attention is all you need 에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도 attention만으로 구현한 모델이다.
이 모델은 RNN을 사용하지 않고도 인코더-디코드 구조를 설계하였음에도? 번역 성능에서 RNN보다 우수한 성능을 보여준다.
기존의 한계
기존의 seq2seq 모델은 인코더-디코더 구조로 이루어져 있는데, 입력 시퀀스를 하나의 벡터 표현으로 압축하고 디코더는 이 벡터를 통해서 출력 시퀀스를 만들어 낸다.
하지만 이 과정에서 입력 시퀀스를 벡터로 압축하는 과정에서 정보가 일부 손실되는 단점이 있었고, 이를 보정하기 위해 어텐션이 사용된다.
트랜스포머
트랜스포머는 RNN을 사용하지 않지만, 인코더 디코더 구조를 유지하고 있긴 하다. 이전의 seq2seq 구조에서 인코더와 디코더에서 하나의 RNN이 t개의 시점을 가지는 구조였다면 이번에는 인코더와 디코더라는 단위가 N개로 구성되는 구조이다.

위의 그림은 인코더와 디코더가 6개씩 존재하는 트랜스포머의 구조이다.
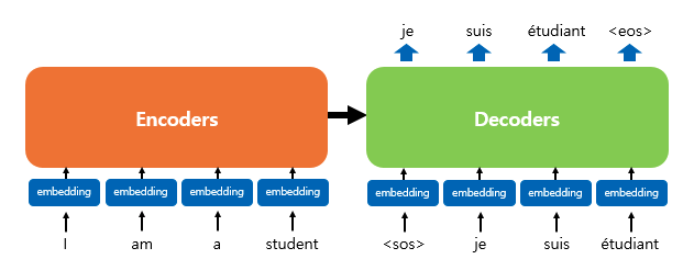
위 그림은 인코더로 부터 정보를 받아 디코더로 출력하는 트랜스포머 구조를 보여준다.
디코더는 seq2seq 구조처럼 시작 심불 <sos> 를 입력받아 종료 심불 <eos> 가 나올 때 까지 연산을 진행한다.
트랜스포머의 인코더와 디코더는 단순히 각 단어의 임베딩 벡터들을 입력받는 것이 아니라 임베딩 벡터에서 조정된 값을 입력받는다.
포지셔널 인코딩
RNN이 자연어 처리에서 유용했던 이유는 단어의 위치에 따라서 단어를 순차적으로 입렫을 받아 처리한다는 특성 때문이였다.
하지만 트랜스포머에서는 단어를 순차적으로 받지 않아서 위치정보를 가질 수 없다.
트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하는데 이를 포지셔널 인코딩이라고 한다.

위의 그림은 입력으로 사용되는 임베딩 벡터들이 트랜스포머의 입력으로 사용되기 전에 포지셔널 인코딩의 값이 더해지는 것을 보여준다.

트랜스포머는 위치 정보를 가진 값을 만들기 위해서 위의 두 개의 함수를 사용한다.
트랜스포머는 사인 함수와 코사인 함수의 값을 임베딩 벡터에 더해주므로서 단어의 순서 정보를 더하여 준다.
임베딩 벡터와 포지셔널 인코딩의 덧셈은
사실 임베딩 벡터가 모여 만들어진 문장 행렬과 포지셔널 인코딩 행렬의 덧셈 연산을 통해 이루어진다.

pos는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, i 는 임베딩 벡터 내의 차원의 인덱스를 의미한다.
위의 식을 따르면 임베딩 벡터 내의 각 차원의 인덱스가 짝수인 경우에는 사인 함수의 값을 사용하고
홀수인 경우에는 코사인 함수의 값을 이용한다.
또한 식에서 d(model)은 트랜스포머의 모든 층의 출력 차원을 의미하는 트랜스포머의 하이퍼파라미터이다.
어텐션

트랜스포머에 사용되는 3가지 어텐션이다.
첫번째 그림인 셀프 어텐션은 인코더에서 이루어지고 두번째 , 세번째는 디코더에서 이루어진다.
셀프어텐션은 본질적으로 Query, key , value 가 동일한 경우(출처가 같다는 말임)를 말하며 세번째 처럼 Query가 디코더의 벡터인 반면에 Key,Value가 인코더의 벡터이므로 셀프 어텐션이라고 부르지 않는다.
인코더의 셀프 어텐션 : Query = Key = Value
디코더의 마스크드 셀프 어텐션 : Query = Key = Value
디코더의 인코더-디코더 어텐션 : Query : 디코더 벡터 / Key = Value : 인코더 벡터

인코더
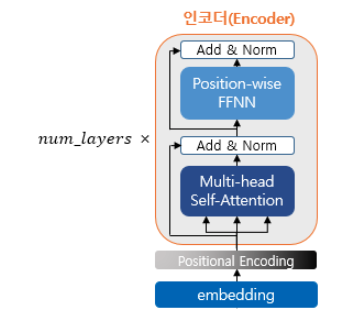
하나의 인코더 층은 크게 총 2개의 서브층으로 나뉘어진다. 셀프어텐션 / 피드 포워드 신경망
위의 그림에서는 멀티 헤드 셀프 어텐션과 포지션 와이즈 피드 포워드 신경망이라고 적혀있지만, 멀티 헤드 셀프 어텐션은 셀프 어텐션을
병렬적으로 사용하였다는 의미고, 포지션 와이즈 피드 포워드 신경망은 우리가 알고있는 일반적인 피드 포워드 신경망이다.
다음번엔 인코더의 셀프 어텐션에 대해서 알아보자
출처: 자연어처리 위키독스
'자연어처리' 카테고리의 다른 글
| [논문리뷰] Template Controllable keywords-to-text Generation (0) | 2024.01.16 |
|---|---|
| GPT-4 Technical Report Review (0) | 2023.09.11 |
| Sequence - to - Sequence ( seq2seq ) (0) | 2023.09.08 |
| Gated Recurrent Unit , GRU ( 게이트 순환 유닛 ) (0) | 2023.09.07 |
| Long Short - Term Memory , LSTM (1) | 2023.09.07 |